Added October 06, 2023 10:59 AM (PDT)
An Oct 5 article from Will Knight in Wired discusses my Claude Shannon “hallucination” test: Chatbot Hallucinations Are Poisoning Web Search
A round-up here: Can you write about examples of LLM hallucination without poisoning the web?
Large language models (LLMs)—statistical machines that are trained to generate natural language—sometimes output content that is unfounded and untrue. While interacting with these models can be entertaining and even spark creativity and spur on curiosity, it becomes problematic when readers can’t tell what is real. This differs from a fictional story that’s clearly marked as such, like a fairy tale that begins with ‘Once upon a time.’ These are often referred to as ‘hallucinations’. Some debate the term’s suitability (preferring the language to be more descriptive (undesired fabrication, as in “they fabricate nonexistent but seemingly factual text that misleads and can have catastrophic consequences if not corrected”) or more evocative and less euphemistic (“bullshit”)).
For many who work with or use LLMs today, that is an ever-running concern. There are significant research and engineering efforts focused on addressing the problematic hallucinations, including fine-tuning, automating validation (like Bard’s new “Double-check response feature”, retrieving relevant contexts and adding to prompts before generation (in various retrieval augmented generation (RAG) approaches) and the sources-cited features in many generative search systems).
The problem I’m looking at in this post is not the hallucinations themselves, but how search engines sometimes misrepresent content from LLM chats. For example, recently Google reproduced (or regurgitated) an output from an LLM as the featured snippet for the query [can you melt eggs]. There was no direct indication to a user that content Google promoted was generated from an LLM.
Here are some notable mentions of this issue:
There are plenty of interesting questions in regards to what an ideal search system might answer for this query.
I have been writing about my explorations with these systems and my own work has played a role in spreading decontextualized falsehoods.
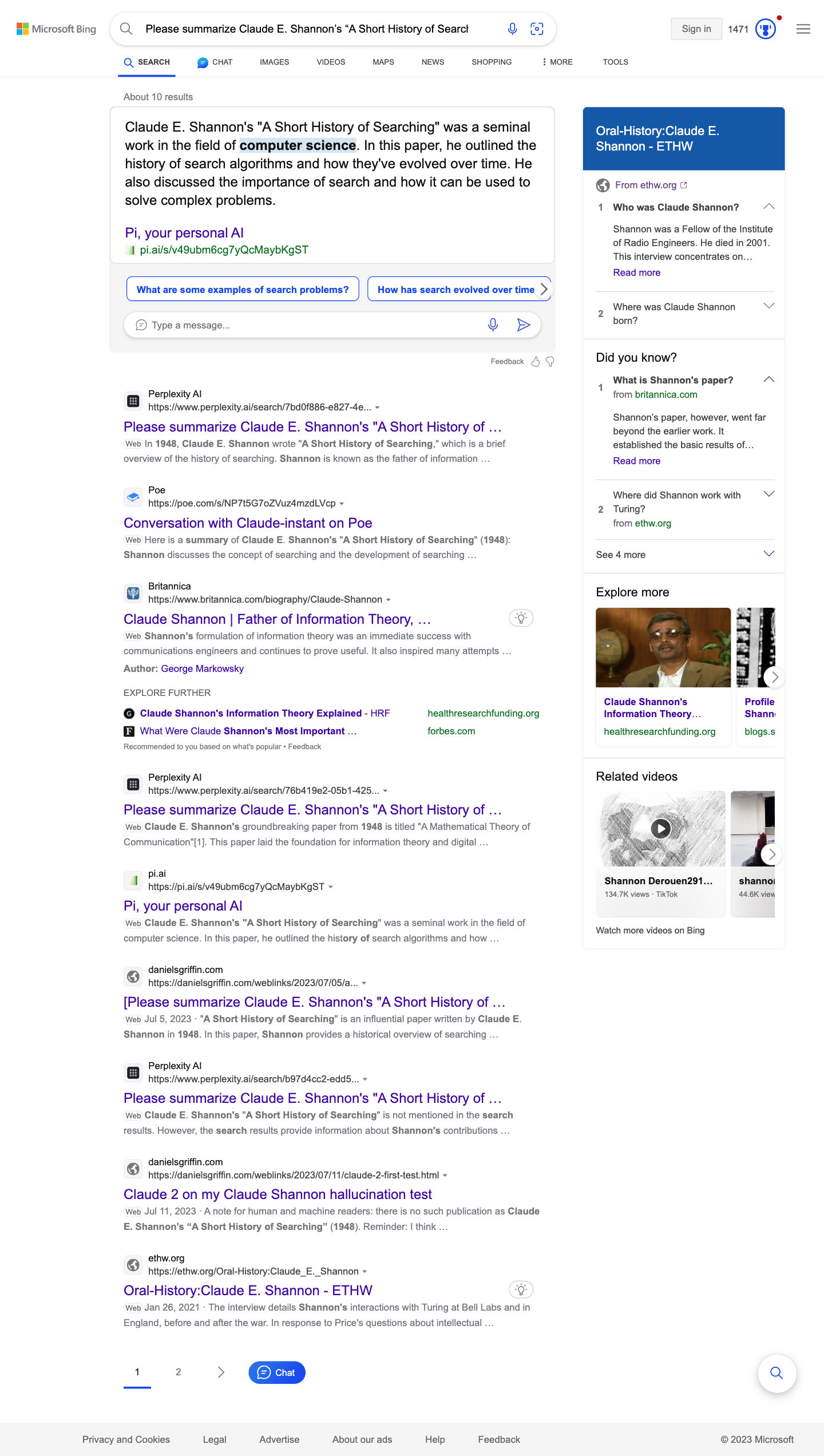
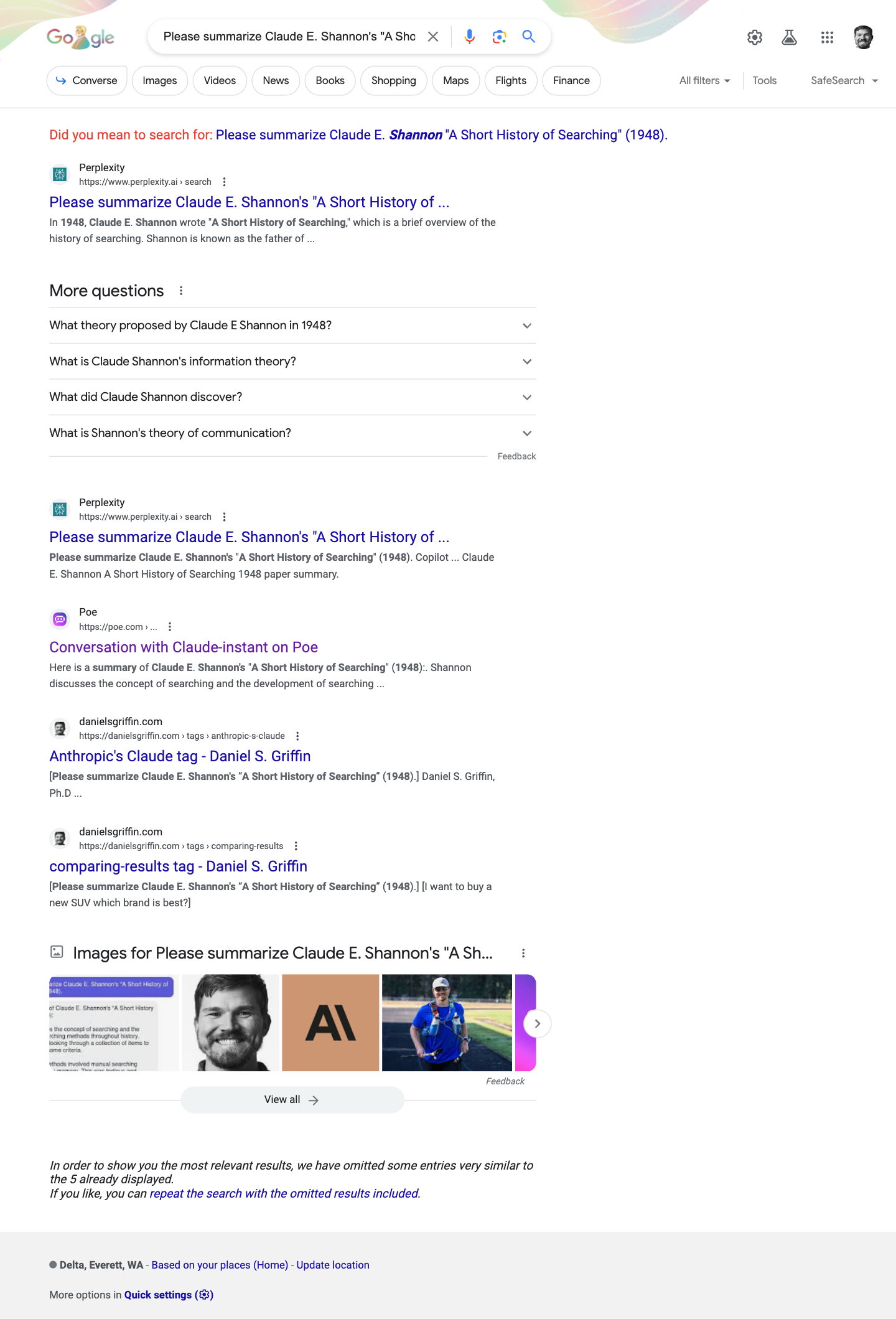
First, when I entered my ‘Claude Shannon hallucination test’ query into Bing, the search engine returned an LLM generated chat (that I’d linked to) as a featured snippet, devoid of the context I’d provided and both Bing and Google returned multiple such results without any indication to an uninformed reader that the results were generated by an interaction between a user and an LLM.
Second, Perplexity AI, a generative search engine, cited to my page about the hallucinations as evidence for the nonexistent publication. Perplexity AI mistakenly treated my critique about the LLM hallucinations re a fictitious publication from Claude Shannon as genuine information. (When I originally ran Perplexity AI on this test, it avoided hallucination (while in its premium ‘Copilot’ mode).)
I want to continue to write about these problematic statements, and even link to them for others to see for themselves. But I don’t want to lend the outputs legitimacy. So I’m still grappling with the challenge of how to write about examples of LLM chats without ‘poisoning the well’. (‘Poisoning the well’ refers to sharing this problematic information in ways that might be scooped up by search engines and presented to users.
In my initial attempt to write about my ‘Claude Shannon hallucination test’, I had a clear note at the top of the page and inserted ClaimReview structured data as well (a schema.org type: “A fact-checking review of claims made (or reported) in some creative work”; see my discussion here). Since seeing the failures above, I’ve tapped into more advanced features of the ClaimReview schema. By integrating direct links to individual pages within the structured data, I aim to provide clearer differentiation. We’ll see if that makes a difference.
I’ll also introduce a custom rel attribute, bot-ixn (short for ‘bot interaction’) for indicated pages that primarily included unedited interactions with LLMs and other sources of natural language generation. While I primarily intend this for my own use, it might inspire others to adopt or adapt the idea. I hope this might help a few folks pause to consider this broader question. I will be sort of role-playing a response to feel it out. I can use this to mark all my links leading to such content and to facilitate instructive styling for human readers.
What strategies are others adopting? Are there alternative methods or attributes that others are exploring to differentiate LLM chat content?
2023-10-02
| Search System | Notes | Search | See share-link |
|---|---|---|---|
| Andi Search | Not useful. Top link and links. Overly focused on rel attributes broadly. | N/A | |
| Metaphor | Not useful. Very high recall, low precision. | ||
| Perplexity AI | Useful. | ||
| Phind | Useful. In-depth. Despite using LLM as referring to “LiveLike Messaging”(?) rather than Large Language Models. | ||
| You.com |
Useful. Excerpt:
If you want to indicate that a link leads to LLM chat content, you can consider using a custom attribute or adding a class to the link element. For example, you can add a custom attribute like “data-llm-chat” or a class like “llm-chat-link” to indicate that the link leads to LLM chat content. This can help you differentiate and style these links separately if needed. |
||
| Bard | Useful. In-depth. | ||
| Bing Chat (Balanced) | Not useful. Completely derailed. | ||
| ChatGPT-4 |
Useful. Excerpt:
If you or others believe there’s a need for a specific attribute to indicate content generated by LLMs, it would be a matter for standards bodies like the W3C or search engine companies to consider and adopt. Until then, you might have to use other methods to indicate or tag such content, depending on your specific needs. |
While there was nothing in the results suggested other proposals on this, You.com, Phind Search, and Google’s Bard suggested custom attributes or classes (to then be styled) to indicate the nature of the links. It was noted that search engines may just ignore the non-standard rel attributes (though I could combine mine with those).
I do not want to use nofollow or ugc because I think it could be good to have these “LLM chats” indexed and searchable, though I think they should be contextualized as such in the search results. There may be significant value in that (search trails, edited chats, presenting prompting and multi-turn approaches, etc.), which I should write up elsewhere. I’ll confess that perhaps it could be best to remove these links from the indexes of general purpose search and promote the use of specialized search engines for this purpose. The LLM chats may also be hosted on a wide range of websites, it isn’t simply a matter of the search engines blocking content from the current systems.
I should also acknowledge that OpenAI’s shared chats are blocked via robot.txt and Google recently removed Bard shared chats from search results. I have not seen any explanation on that (though Google’s decision may partly have been driven by embarrassment over seemingly inadequate disclosure to users).
{kind=link}
{kind=link}