I’ve been reflecting further on the article by Davey Alba from yesterday (“Even Google Insiders Are Questioning Bard AI Chatbot’s Usefulness” (Bloomberg)) (see [weblink] here), and comments after from Grady Booch, Melanie Mitchell, Gary Marcus, and Jack Krawczyk (the product lead for Bard).
My initial concerns related to the Bard Discord can be found in my quoted comments.1
However, the subsequent reporting and comments have raised a distinct set of concerns about explainability, trust, and how users come to understand and use the tool.2 How might Google help users calibrate their trust and understanding within the tool itself? What is Google’s responsibility here? I’ve long held similar concerns regarding Google’s core search products.3
The comments from Google employees in the Discord raise concerns about what Google is doing (in the interface itself) to help Bard users calibrate trust, develop awareness of “hallucination” and other limitations, and take on the delegated responsibility for verification.
I’m thinking about these sorts of questions: What is Google doing to support users in developing their own “practical knowledge” of Bard (Cotter, 2022)?4 Is Google still “upfront about its limitations”?5 How helpful are the explanations?6 How do we know?
Currently Bard is labeled as an “Experiment”, there is a small disclaimer (“Bard may display inaccurate or offensive information that doesn’t represent Google’s views.”), and the welcome message currently includes a short qualifier: “…I have limitations and won’t always get it right…” (see image below).
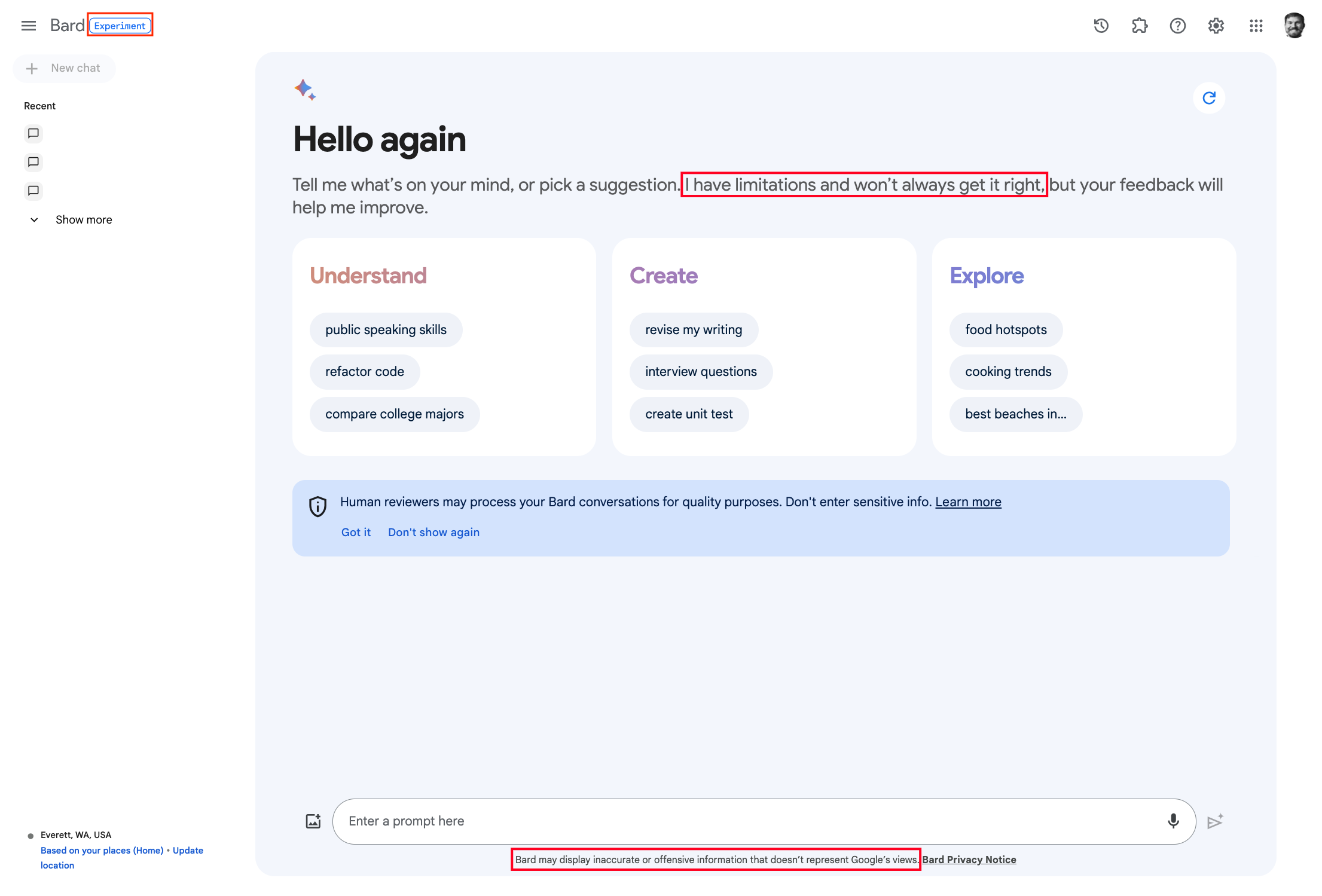
I can’t help but wonder how perceptions and usage of the tool might change if warnings like the comments from Google employees in the Bard Discord or elsewhere were presented in the interface. Perhaps if there were bold text that said:
Some Google employees warn:
Bard is “tricky”
Bard is “a pathological liar”
And that “we all have to be responsible in each step along the way”7
Here’s a speculative design of the Bard main page, highlighting warnings from employees:
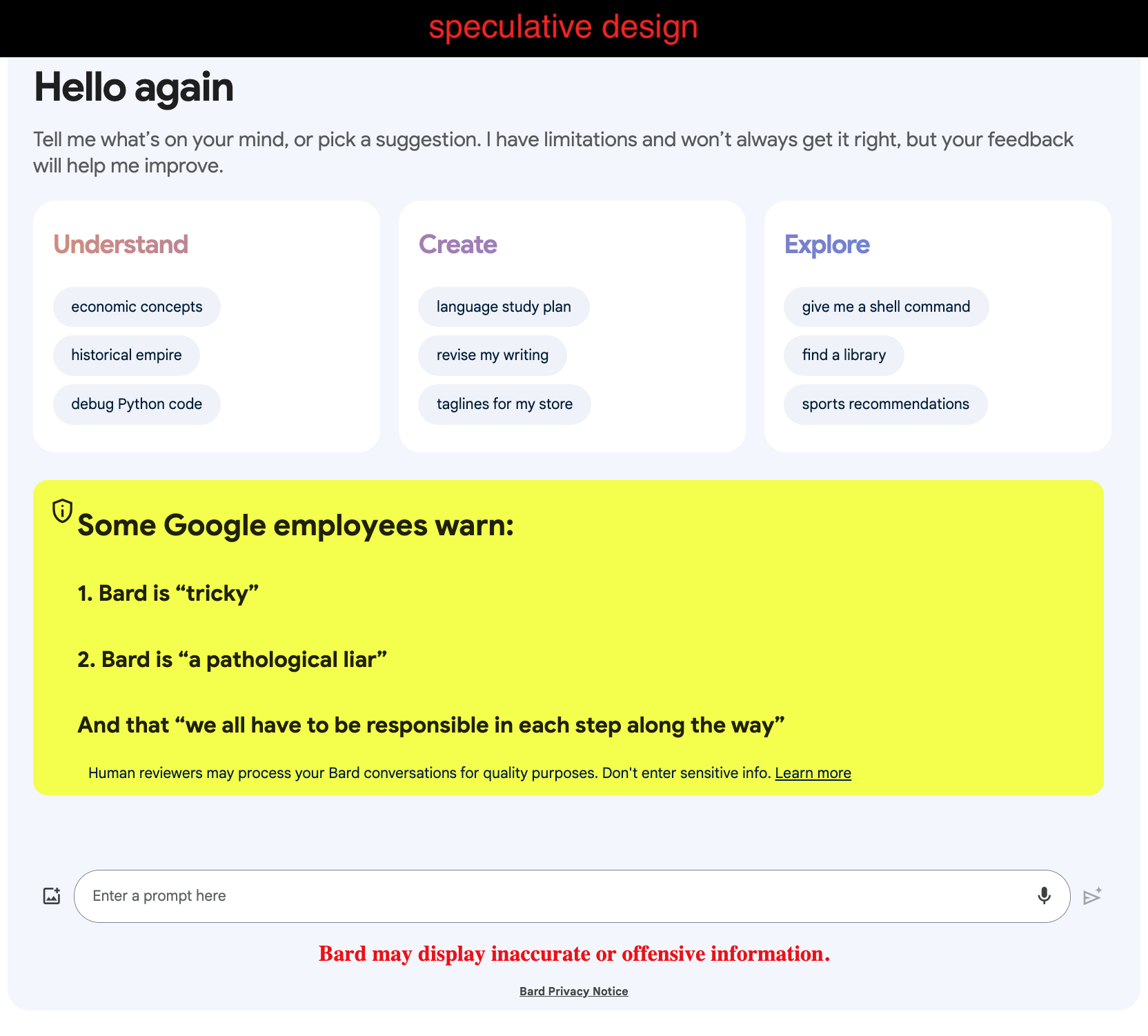
Of course that is entirely unrealistic. But what could be done?
Recommended reading
- Nora Freya Lindemann’s work (2023a, 2023b) on doubting the outputs of LLMs or unsealing knowledge [ppost]
Footnotes
This analysis was refined while working with Emma Lurie on “Search quality complaints and imaginary repair: Control in articulations of Google Search” (2022). We built atop prior work looking at how people work together to collectively learn about ‘algorithms’ and how to use them, including work I was involved with (Burrell et al., 2019).↩︎
For years I’ve wondered about where the principles in Google’s People + AI Guidebook on Explainability + Trust seem to be followed and where not.↩︎
For example:
- search automation bias
- “Rescripting Search to Respect the Right to Truth” (Mulligan & Griffin, 2018)
- A Speculative Search Box Autosuggest Advice Interface
- harm reducing interstitials[^1]
- contextual help re results estimates
- how people do or don’t learn about search
Many others have discussed the evidence for and causes of miscalibrated, misconveyed, or misplaced trust in Google search, including: Pan et al. (2007); Hendry & Efthimiadis (2008); Tripodi (2018); Smith & Rieh (2019); Haider & Sundin (2022); Narayanan & De Cremer (2022).
I’ve also been thinking a lot about how to support users in developing practical knowledge of generative AI systems as well:- sharing interfaces
- tools in evaluating generative web search platforms
- is it obvious these tools are powerful?
- “unsealing knowledge”
- exploring calibration tools/games
Note this Bard Discord is very small in comparison to the number monthly users of Bard.↩︎
From Alba (linked at top): “At Bard’s launch, the company was upfront about its limitations, including about the possibility for the AI tool to generate convincing-sounding lies.”↩︎
The phrase ‘helpful’, here, is drawn from a Google write-up: “3 emerging practices for responsible generative AI”: “3. Communicate simple, helpful explanations.”↩︎
The “tricky” comment is taken from a March 21 article from Nico Grant and Cade Metz: “Google Releases Bard, Its Competitor in the Race to Create A.I. Chatbots” (New York Times). The “a pathological liar” comment is taken from an April 19 article from Davey Alba and Julia Love: “Google’s Rush to Win in AI Led to Ethical Lapses, Employees Say” (Bloomberg). The “we all have to be responsible in each step along the way” comment is taken from an April 16 segment from Scott Pelley: “Is artificial intelligence advancing too quickly? What AI leaders at Google say” (CBS).↩︎
References
Burrell, J., Kahn, Z., Jonas, A., & Griffin, D. (2019). When users control the algorithms: Values expressed in practices on Twitter. Proc. ACM Hum.-Comput. Interact., 3(CSCW). https://doi.org/10.1145/3359240 [burrell2019control]
Cotter, K. (2022). Practical knowledge of algorithms: The case of BreadTube. New Media & Society, 1–20. https://doi.org/10.1177/14614448221081802 [cotter2022practical]
Griffin, D., & Lurie, E. (2022). Search quality complaints and imaginary repair: Control in articulations of Google Search. New Media & Society, 0(0), 14614448221136505. https://doi.org/10.1177/14614448221136505 [griffin2022search]
Haider, J., & Sundin, O. (2022). Paradoxes of media and information literacy. Routledge. https://doi.org/10.4324/9781003163237 [haider2022paradoxes]
Hendry, D. G., & Efthimiadis, E. N. (2008). Conceptual models for search engines. In A. Spink & M. Zimmer (Eds.), Web search: Multidisciplinary perspectives (pp. 277–307). Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-75829-7_15 [hendry2008conceptual]
Lindemann, N. F. (2023a, August). Sealed knowledges: A critical approach to the usage of llms as search engines. Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. https://doi.org/10.1145/3600211.3604737 [lindemann2023sealed_paper]
Lindemann, N. F. (2023b). Sealed knowledges: A critical approach to the usage of llms as search engines. https://doi.org/10.13140/RG.2.2.18050.04800 [lindemann2023sealed_poster]
Mulligan, D. K., & Griffin, D. (2018). Rescripting search to respect the right to truth. The Georgetown Law Technology Review, 2(2), 557–584. https://georgetownlawtechreview.org/rescripting-search-to-respect-the-right-to-truth/GLTR-07-2018/ [mulligan2018rescripting]
Narayanan, D., & De Cremer, D. (2022). “Google told me so!” On the bent testimony of search engine algorithms. Philos. Technol., 35(2), E4512. https://doi.org/10.1007/s13347-022-00521-7 [narayanan2022google]
Pan, B., Hembrooke, H., Joachims, T., Lorigo, L., Gay, G., & Granka, L. (2007). In google we trust: Users’ decisions on rank, position, and relevance. Journal of Computer-Mediated Communication, 12(3), 801–823. https://doi.org/10.1111/j.1083-6101.2007.00351.x [pan2007google]
Smith, C. L., & Rieh, S. Y. (2019, March). Knowledge-context in search systems. Proceedings of the 2019 Conference on Human Information Interaction and Retrieval. https://doi.org/10.1145/3295750.3298940 [smith2019knowledge]
Tripodi, F. (2018). Searching for alternative facts: Analyzing scriptural inference in conservative news practices. Data & Society. https://datasociety.net/output/searching-for-alternative-facts/ [tripodi2018searching]